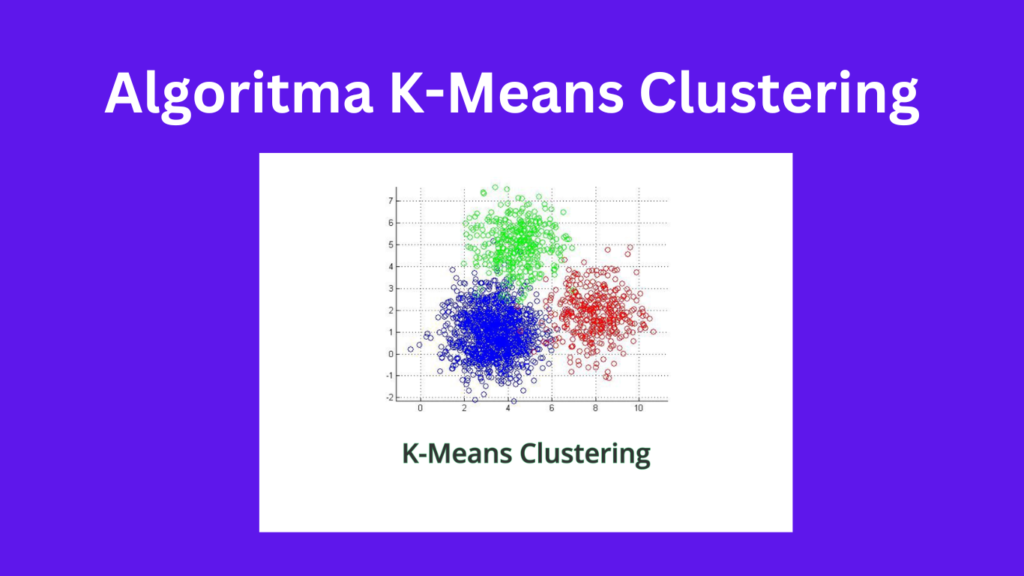
Algoritma K-Means Clustering adalah algoritma yang digunakan untuk mengelompokkan data menjadi beberapa kelompok berdasarkan pada kesamaan karakteristiknya. Metode ini sangat umum digunakan dalam analisis data, pengelompokkan objek, dan segmentasi pelanggan. Dalam artikel ini, akan dijelaskan secara detail tentang algoritma K-Means Clustering dan bagaimana cara kerjanya.
Apa itu K-Means Clustering?
K-Means Clustering adalah salah satu metode pengelompokkan data yang paling sederhana dan populer. Algoritma ini mengelompokkan data berdasarkan jarak antara titik data. Tujuannya adalah untuk mengelompokkan titik-titik data ke dalam kumpulan atau kelompok yang homogen berdasarkan pada kesamaan atribut.
Algoritma ini mengelompokkan data dengan cara mencari titik pusat dari masing-masing kelompok atau centroid. Pusat kelompok atau centroid merupakan rata-rata dari titik-titik data di dalam kelompok tersebut. Algoritma K-Means Clustering bekerja dengan cara mengulang proses pengelompokkan hingga didapatkan kelompok yang stabil atau tidak berubah.
Bagaimana cara kerja K-Means Clustering?
Algoritma K-Means Clustering bekerja dengan cara mengelompokkan titik-titik data ke dalam kelompok berdasarkan pada jarak antara titik data. Cara kerjanya adalah sebagai berikut:
- Tentukan jumlah kelompok atau cluster yang diinginkan.
- Tentukan titik awal untuk setiap kelompok atau centroid secara acak.
- Hitung jarak antara setiap titik data dengan setiap centroid.
- Masukkan setiap titik data ke dalam kelompok yang memiliki centroid terdekat.
- Hitung rata-rata atau centroid baru untuk setiap kelompok yang terbentuk.
- Ulangi proses pengelompokkan dengan menggunakan centroid baru hingga tidak terjadi perubahan kelompok lagi.
Proses ini terus berulang hingga didapatkan kelompok yang stabil atau tidak berubah. Hasil akhir dari algoritma K-Means Clustering adalah beberapa kelompok yang terbentuk berdasarkan pada kesamaan atribut.
Contoh penggunaan K-Means Clustering
Untuk memahami cara kerja algoritma K-Means Clustering, berikut adalah contoh penggunaannya dalam pengelompokkan data pelanggan toko online.
- Tentukan jumlah kelompok atau cluster yang diinginkan, misalnya 3.
- Pilih secara acak 3 titik data sebagai titik awal untuk masing-masing kelompok.
- Hitung jarak antara setiap titik data dengan setiap centroid.
- Masukkan setiap titik data ke dalam kelompok yang memiliki centroid terdekat.
- Hitung rata-rata atau centroid baru untuk setiap kelompok yang terbentuk.
- Ulangi proses pengelompokkan dengan menggunakan centroid baru hingga tidak terjadi perubahan kelompok lagi.
Hasil akhir dari algoritma K-Means Clustering adalah beberapa kelompok yang terbentuk berdasarkan pada
kesamaan atribut. Dalam contoh ini, kelompok-kelompok yang terbentuk mungkin berdasarkan pada atribut seperti usia, jenis kelamin, dan riwayat pembelian.
Misalnya, jika kita menggunakan atribut usia, maka kelompok-kelompok yang terbentuk mungkin adalah:
- Kelompok 1: Pelanggan muda (<25 tahun)
- Kelompok 2: Pelanggan dewasa (25-45 tahun)
- Kelompok 3: Pelanggan tua (>45 tahun)
Setelah dilakukan pengelompokkan, kita dapat melakukan analisis lebih lanjut untuk memahami karakteristik dan preferensi pelanggan di setiap kelompok. Dengan demikian, toko online dapat menyusun strategi pemasaran yang lebih efektif untuk masing-masing kelompok pelanggan.
Kelebihan dan Kekurangan K-Means Clustering
Kelebihan dari algoritma K-Means Clustering adalah:
- Sangat cepat dan efisien dalam mengelompokkan data.
- Mudah dipahami dan diimplementasikan.
- Cocok untuk data yang memiliki jumlah variabel yang banyak.
- Dapat mengatasi data yang bersifat kontinu maupun diskrit.
Namun, algoritma K-Means Clustering juga memiliki kekurangan, yaitu:
- Sangat sensitif terhadap pemilihan jumlah kelompok atau cluster awal.
- Tidak cocok untuk data yang memiliki banyak outlier atau pencilan.
- Tidak dapat menangani data yang memiliki kelompok yang berbentuk tidak bulat atau berbentuk aneh.
Kesimpulan
Algoritma K-Means Clustering adalah salah satu metode pengelompokkan data yang paling sederhana dan populer. Algoritma ini mengelompokkan data berdasarkan jarak antara titik data dan mengulang proses pengelompokkan hingga didapatkan kelompok yang stabil atau tidak berubah. Meskipun memiliki kekurangan, algoritma K-Means Clustering sangat berguna untuk mengelompokkan data dan membantu analisis data lebih efektif.